実験2
前回の続きです.
データを生成する分布として次のような複合分布を考えます.
$$ X \sim \mathrm{Bernoulli}(q) $$ $$ q \sim \mathrm{Beta}(a, b) $$ これはベルヌーイ分布のパラメータ$q$の事前分布がベータ分布$\mathrm{Beta}(a, b)$にしたがう複合分布です.
パラメータ$q$を消去すればこの複合分布は ベータ2項分布 $$ X \sim \mathrm{Betabinomial}(1,a,b) $$ と一致します.
このベータ2項分布からデータを生成し,「正しい」統計モデルで分析します.
つまり $$ X \sim \mathrm{Bernoulli}(q) $$
$$ q \sim \mathrm{Beta}(a, b) $$ というベイズ統計モデルを仮定して自由エネルギーを計算したらどうなるかを実験して確かめます.
まずデータを生成するためにRのextraDistrパッケージを使い,ベータ2項分布にしたがう確率変数の実現値を100個つくります.
> library(extraDistr) > rbbinom(100, 1, alpha = 2, beta = 8) [1] 1 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 1 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 [43] 0 0 1 0 1 0 0 0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 1 0 1 1 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 [85] 1 0 0 0 1 1 0 0 0 0 0 0 0 0 1 0
このデータを使って自由エネルギーを計算します.
> Fn(x,a=2,b=8) [1] 49.84582 > Fn(x,a=20,b=80) [1] 48.97739 > Fn(x,a=200,b=800) [1] 48.69709
念のため,Mathematicaでも同種のデータを生成します.
In[1]:= (* ベータ2項分布からの実現値生成 *) x = RandomVariate[ BetaBinomialDistribution[2, 8, 1], 100] Out[1]= {1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, \ 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, \ 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, \ 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, \ 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1} In[2]:= Mean[x] Out[2]= 9/50
自由エネルギーを定義して計算してみましょう.
In[4]:= FEnergy[x_, a_, b_] := N[-1*Log[Beta[Total[x] + a, Length[x] - Total[x] + b]/Beta[a, b]]]; In[5]:= FEnergy[x, 2, 8] FEnergy[x, 20, 80] FEnergy[x, 200, 800] FEnergy[x, 2000, 8000] FEnergy[x, 20000, 80000] Out[5]= 48.3529 Out[6]= 47.5336 Out[7]= 47.3005 Out[8]= 47.271 Out[9]= 47.268
さすがはMathematica.パラメータが20000,80000でも余裕で計算してくれます(Rだと200,800が限界でそれ以上は計算してくれない.そういうとこやぞ).
どちらも同じような結果になりました. さてデータを生成する分布として$\mathrm{BetaBinomial}(n=1,a=2,b=8)$を仮定していますが, データから計算した平均の最尤推定値は9/50です.
次に事前分布の平均値が9/50になるようなモデルの自由エネルギーを計算してみます.
N[FEnergy[x, 180000, 820000], 10 ] N[FEnergy[x, 1800000, 8200000], 10 ] N[FEnergy[x, 18000000, 82000000], 10 ] 47.13939868 47.13935368 47.13934918
真のモデルよりも小さい? 自由エネルギーは確率変数なので,データの出方によってばらつきがあります.以上の計算をふまえ,データを複数回生成することで自由エネルギーの平均を比較します.
out <- c()#真の事前分布beta(2,8)の自由エネルギー for(i in 1:3000){ x <- rbbinom(1000, 1, alpha = 2, beta = 8) out <- append(out,Fn(x,a=2,b=8)) } out2 <- c()# 事前分布beta(20,80)の自由エネルギー for(i in 1:3000){ x <- rbbinom(1000, 1, alpha = 2, beta = 8) out2 <- append(out2,Fn(x,a=20,b=80)) } out3 <- c()# MLの自由エネルギー for(i in 1:3000){ x <- rbbinom(1000, 1, alpha = 2, beta = 8) out3 <- append(out3,-1*log(mean(x)^(sum(x))*(1-mean(x))^(length(x)-sum(x)))) }
結果を比較すると......
最尤法モデル<ベイズモデル beta(20,80) <ベイズモデル beta(2,8)
となりました. 真の分布と同じ統計モデル(確率モデル+事前分布)の平均自由エネルギーより,最尤推定モデルに近いベイズモデルや最尤推定モデルの平均自由エネルギーのほうが小さいことが分かりました*1.
統計モデルが真の分布に一致している場合よりも,事前分布が最尤推定値に質点を持つディラックデルタ分布に近い方が,この条件下では自由エネルギーの平均値が小さくなっています.このことから自由エネルギーによるモデル選択は,データを生成した分布よりも,観察したデータそのものに尤度の意味で近い統計モデルを選んでいるらしいと考えられます.なぜこうなってしまうのでしょうか?引き続き考えてみます.
実験3
さきほどの実験では,$\mathrm{BetaBinomial}(n=1,a=2,b=8)$からデータを生成しましたが,そもそもこのデータでは複合分布を周辺化した結果がベルヌーイ分布と一致するので例としては特殊すぎた可能性があります.
違う条件で計算してみるとどうなるのでしょうか? 自由エネルギーによるモデル選択は最大対数尤度による選択と一致するのでしょうか?
実験3の設定は次の通りです.はじめにデータを $$ X \sim \mathrm{Poisson}(\lambda) $$
$$ \lambda \sim \mathrm{Gamma}(a, b) $$ という結合分布から生成します.よく知られているように,この仮定の下で$\lambda$を周辺化すると,$X$は負の2項分布に従うことが知られています. したがってデータを $$ X \sim \mathrm{NegativeBinomial}(a, 1/(b+1)) $$ から生成したと考えても同じことです. 以下では$a=1, b=3$を仮定してデータを生成します($n=100$のデータを作りました).
In[3]:= x = RandomVariate[NegativeBinomialDistribution[1, 0.25], 100] Out[3]= {5, 0, 2, 1, 3, 5, 2, 9, 2, 0, 8, 2, 13, 2, 2, 0, 6, 0, 3, 6, \ 4, 0, 1, 4, 1, 19, 2, 8, 0, 1, 0, 1, 5, 4, 3, 0, 5, 0, 9, 0, 3, 0, \ 17, 1, 10, 5, 2, 8, 1, 0, 2, 2, 4, 0, 0, 9, 2, 0, 0, 3, 3, 2, 5, 0, \ 0, 2, 0, 2, 1, 1, 4, 0, 7, 0, 1, 21, 5, 6, 0, 0, 0, 7, 4, 0, 0, 0, 0, \ 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0}
このデータをベイズモデル $$ X \sim \mathrm{Poisson}(\lambda) $$
$$ \lambda \sim \mathrm{Gamma}(a, b) $$ で学習して自由エネルギーを計算します. するとこのベイズモデルの自由エネルギーは $$ F_n=-\log\Gamma\left(\sum x_i+a\right) +\log \Gamma(a)+\sum \log x_i ! -a\log b +\left(\sum x_i +a\right)\log (n+b) $$ です(浜田・石田・清水2019: 111).
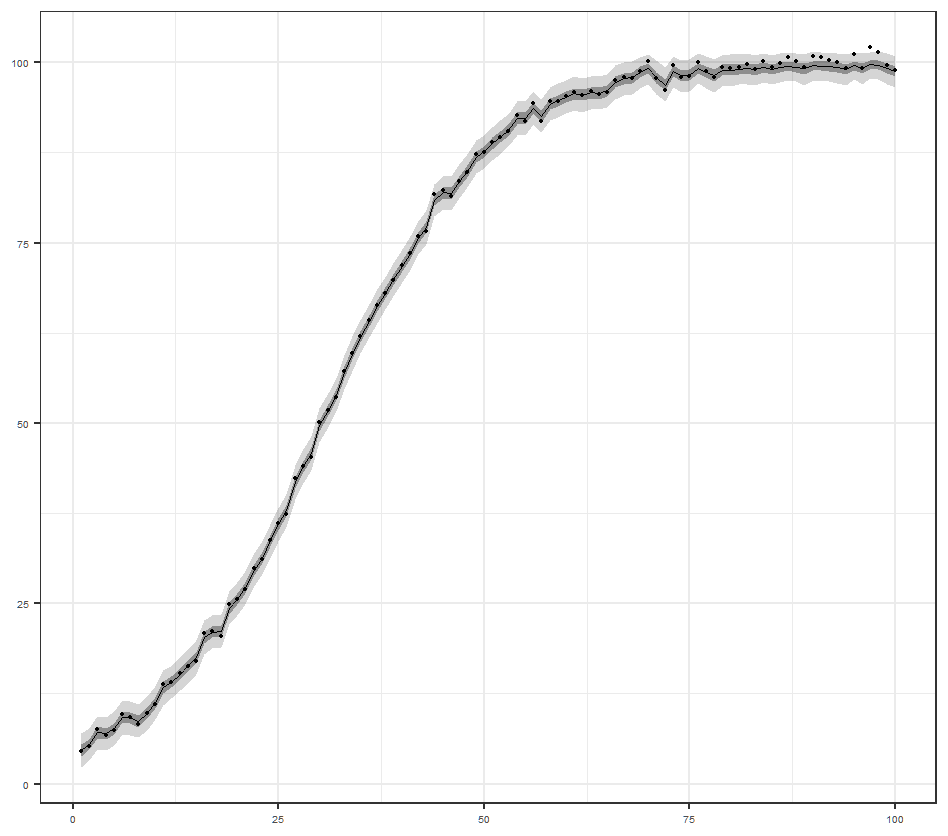
自由エネルギーの引数はデータ$x_1, x_2, ... x_n$とパラメータ$a, b$です.このうちデータと片方のパラメータの真値$a=1$が与えられたとして,$b$の変化による自由エネルギーの変化を確認してみましょう.

データを生成したパラメータは$a=1, b=3$ですから,$b=3$のとき最も小さくなることを予想していましたが,全く違う箇所で最小化しているようです.
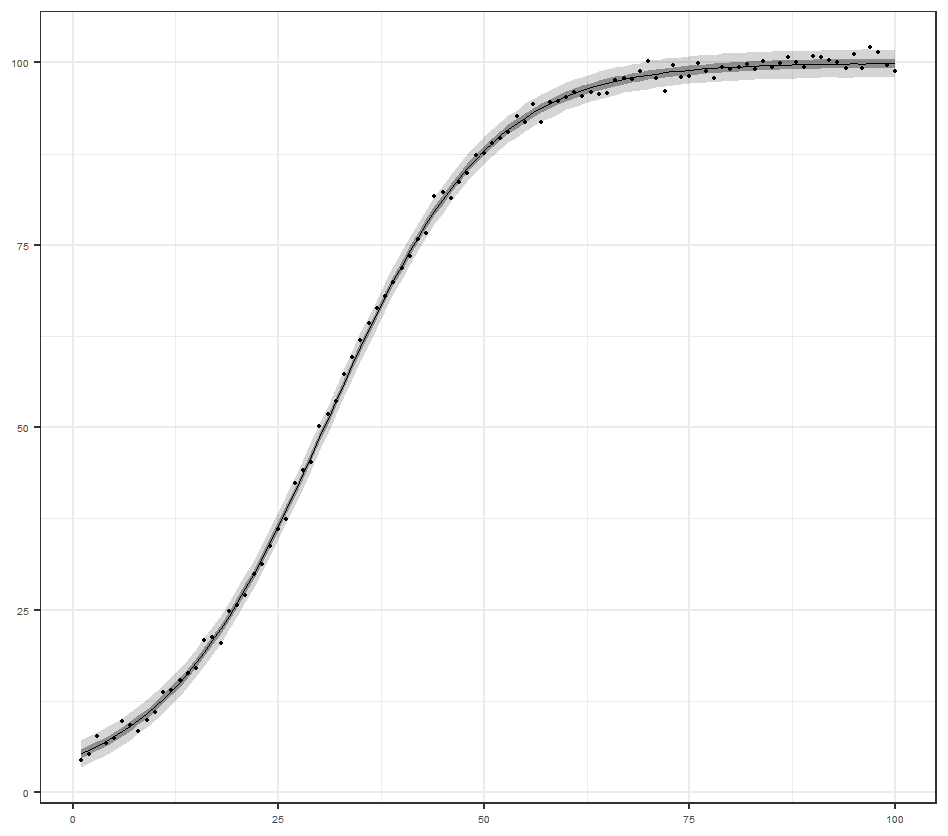
次にデータを生成した負の2項分布ではなく,ポアソン分布を確率モデルとして使った場合の自由エネルギーを計算します.事前分布としてデータの平均の最尤推定値に質点をもつようなディラックデルタ分布を仮定します.つまりポアソン分布で最尤推定した場合の対数尤度の符号反転を自由エネルギーとして定義します.
ポアソン分布のパラメータ$\lambda$の変化にともなう自由エネルギーの変化は次の通りです.

このデータの平均の最尤推定値は2.84なので,自由エネルギーの定義上,$\lambda=2.84$のとき最小化します.
サンプルサイズ1000のデータセットを3000回発生させ,自由エネルギーを計算した結果を比較します.もはやRでは実行できないのでMathematicaに計算してもらいます.
Module[{xvec, out, out2}, out = {samplesize = 1000, itr = 3000}; Do[ xvec = RandomVariate[NegativeBinomialDistribution[1, 0.25], samplesize]; out = Append[out, Fn[xvec, 1, 3]], {itr} ]; out2 = {}; Do[ xvec = RandomVariate[NegativeBinomialDistribution[1, 0.25], samplesize]; out2 = Append[out2, Fnpois[xvec, Mean[xvec]]], {itr} ]; Print[{Mean[out], Mean[out2]}]; Histogram[{out, out2}] ]

自由エネルギーの平均値は,
ポアソンモデル 2899.84 < データを生成した分布(負の2項分布) 2910.24
でした.この条件でも平均自由エネルギーはデータを生成したモデルを選択しません.定義上,自由エネルギーの平均値は真のモデルと周辺尤度の交差エントロピーなので,周辺尤度を真の分布と一致するように作れば,自由エネルギーの平均も最小化するはずです.
式で書くと $$ \begin{align} E_{q(X^{n})}[F_n]&=-\int q(x^{n})\log p(x^{n}) dx^{n} \\ &=H[q(X^{n})]+D[q(X^{n})||p(X^{n})] \end{align} $$ なので,自由エネルギーの平均は真の分布のエントロピーと真の分布と周辺尤度のKL距離に分解できます.このうちKL距離は真の分布$q(X^{n})$と周辺尤度$p(X^{n})$ が一致しているのでゼロです.
しかし上記の条件では,データを発生させる真の分布とは異なる確率モデルのもとで,自由エネルギーがより小さな値をとっています.
なぜこうなるのか正直よく分かりません.原因が判明したら追記します.